

El futuro del aprendizaje profundo se puede dividir en estos 3 paradigmas de aprendizaje

El futuro del aprendizaje profundo se puede dividir en estos 3 paradigmas de aprendizaje
Aprendizaje híbrido, compuesto y reducido
Sitio web original:
El aprendizaje profundo es un campo amplio, centrado en torno a un algoritmo cuya forma está determinada por millones o incluso miles de millones de variables y se modifica constantemente: la red neuronal. Parece que cada dos días se proponen cantidades abrumadoras de nuevos métodos y técnicas.
Sin embargo, en general, el aprendizaje profundo en la era moderna se puede dividir en tres paradigmas de aprendizaje fundamentales. Dentro de cada uno se encuentra un enfoque y una creencia hacia el aprendizaje que ofrece un potencial e interés significativos para aumentar el poder y el alcance actuales del aprendizaje profundo.
Aprendizaje híbrido — ¿Cómo pueden los métodos modernos de aprendizaje profundo cruzar los límites entre el aprendizaje supervisado y no supervisado para dar cabida a una gran cantidad de datos no etiquetados no utilizados?
aprendizaje compuesto — ¿Cómo se pueden conectar diferentes modelos o componentes en métodos creativos para producir un modelo compuesto mayor que la suma de sus partes?
Aprendizaje reducido — ¿Cómo se puede reducir tanto el tamaño como el flujo de información de los modelos, tanto para fines de rendimiento como de implementación, manteniendo el mismo poder predictivo o mayor?
El futuro del aprendizaje profundo se encuentra en estos tres paradigmas de aprendizaje, cada uno de los cuales está fuertemente interconectado.
Aprendizaje híbrido
Este paradigma busca cruzar los límites entre el aprendizaje supervisado y no supervisado. A menudo se usa en el contexto de los negocios debido a la falta y al alto costo de los datos etiquetados. En esencia, el aprendizaje híbrido es una respuesta a la pregunta,
¿Cómo puedo usar métodos supervisados para resolver/junto con problemas no supervisados?
Por un lado, el aprendizaje semisupervisado está ganando terreno en la comunidad de aprendizaje automático por ser capaz de funcionar excepcionalmente bien en problemas supervisados con pocos datos etiquetados. Por ejemplo, una GAN (Generative Adversarial Network) semisupervisada bien diseñada logró más del 90 % de precisión en el conjunto de datos MNIST después de ver solo 25 ejemplos de entrenamiento.
El aprendizaje semisupervisado está diseñado para conjuntos de datos en los que hay muchos datos no supervisados pero pequeñas cantidades de datos supervisados. Mientras que tradicionalmente un modelo de aprendizaje supervisado se entrenaría en una parte de los datos y un modelo no supervisado en la otra, un modelo semisupervisado puede combinar datos etiquetados con conocimientos extraídos de datos no etiquetados.
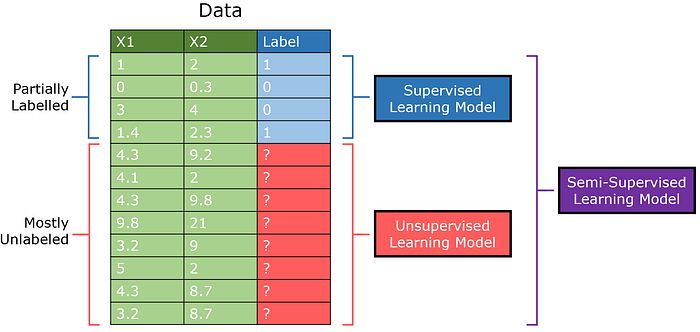
El GAN semi-supervisado (abreviado como SGAN), es una adaptación del estándar Modelo de red adversaria generativa. El discriminador emite 0/1 para indicar si se genera una imagen o no, pero también emite la clase del elemento (aprendizaje de múltiples salidas).
Esto se basa en la idea de que a través del discriminador que aprende a diferenciar entre imágenes reales y generadas, puede aprender sus estructuras sin etiquetas concretas. Con el refuerzo adicional de una pequeña cantidad de datos etiquetados, los modelos semisupervisados pueden lograr un rendimiento superior con cantidades mínimas de datos supervisados.
Puede leer más sobre las SGAN y el aprendizaje semisupervisado aquí.
Los GAN también están involucrados en otra área de aprendizaje híbrido: auto-supervisado aprendizaje, en el que los problemas no supervisados se enmarcan explícitamente como supervisados. Las GAN crean artificialmente datos supervisados mediante la introducción de un generador; se crean etiquetas para identificar imágenes reales/generadas. A partir de una premisa no supervisada, se creó una tarea supervisada.
Alternativamente, considere el uso de modelos de codificador-decodificador para compresión. En su forma más simple, son redes neuronales con una pequeña cantidad de nodos en el medio para representar algún tipo de forma comprimida de cuello de botella. Las dos secciones a cada lado son el codificador y el decodificador.
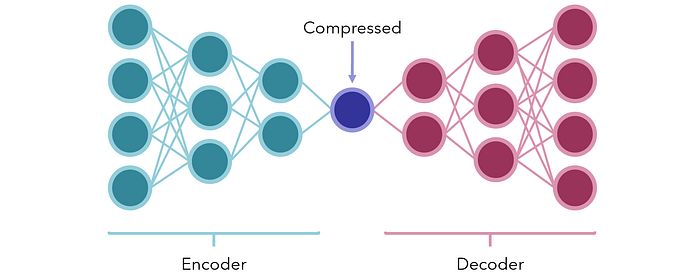
La red está capacitada para producir la mismo salida como la entrada del vector (una tarea supervisada creada artificialmente a partir de datos no supervisados). Debido a que hay un cuello de botella colocado deliberadamente en el medio, la red no puede pasar la información pasivamente; en cambio, debe encontrar las mejores formas de preservar el contenido de la entrada en una unidad pequeña de modo que el decodificador pueda decodificarlo razonablemente nuevamente.
Una vez entrenados, el codificador y el decodificador se desarman y se pueden usar en los extremos de recepción de datos comprimidos o codificados para transmitir información en forma extremadamente pequeña con poca o ninguna pérdida de datos. También se pueden utilizar para reducir la dimensionalidad de los datos.
Como otro ejemplo, considere una gran colección de textos (quizás comentarios de una plataforma digital). A través de algún agrupamiento o aprendizaje múltiple método, podemos generar etiquetas de clúster para colecciones de textos, luego tratarlos como etiquetas (siempre que el agrupamiento esté bien hecho).
Después de que se interpreta cada grupo (por ejemplo, el grupo A representa comentarios que se quejan de un producto, el grupo B representa comentarios positivos, etc.) una arquitectura profunda de NLP como BERT luego se puede usar para clasificar nuevos textos en estos grupos, todo con datos completamente sin etiquetar y una participación humana mínima.
Esta es una vez más una aplicación fascinante de convertir tareas no supervisadas en supervisadas. En una era en la que la gran mayoría de todos los datos son datos no supervisados, existe un enorme valor y potencial en la construcción de puentes creativos para cruzar los límites entre el aprendizaje supervisado y no supervisado con el aprendizaje híbrido.
Aprendizaje compuesto
El aprendizaje compuesto busca utilizar el conocimiento no de un modelo sino de varios. Es la creencia de que a través de combinaciones únicas o inyecciones de información, tanto estáticas como dinámicas, el aprendizaje profundo puede profundizar continuamente en la comprensión y el rendimiento que un solo modelo.
El aprendizaje por transferencia es un ejemplo obvio de aprendizaje compuesto y se basa en la idea de que los pesos de un modelo pueden tomarse prestados de un modelo previamente entrenado en una tarea similar y luego ajustarse en una tarea específica. Modelos preentrenados como Comienzo o VGG-16 están construidos con arquitecturas y pesos diseñados para distinguir entre varias clases diferentes de imágenes.
Si tuviera que entrenar una red neuronal para reconocer animales (gatos, perros, etc.), no entrenaría una red neuronal convolucional desde cero porque llevaría demasiado tiempo lograr buenos resultados. En su lugar, tomaría un modelo preentrenado como Inception, que ya ha almacenado los conceptos básicos del reconocimiento de imágenes, y entrenaría algunas épocas adicionales en el conjunto de datos.
De manera similar, las incrustaciones de palabras en las redes neuronales de NLP, que asignan palabras físicamente más cerca de otras palabras en un espacio de incrustación según sus relaciones (por ejemplo, 'manzana' y 'naranja' tienen distancias más pequeñas que 'manzana' y 'camión'). Las incrustaciones preentrenadas como GloVe se pueden colocar en redes neuronales para comenzar desde lo que ya es un mapeo efectivo de palabras a entidades numéricas y significativas.
Menos obviamente, la competencia también puede estimular el crecimiento del conocimiento. Por un lado, las Redes adversarias generativas toman prestado del paradigma de aprendizaje compuesto al enfrentar fundamentalmente dos redes neuronales entre sí. El objetivo del generador es engañar al discriminador, y el objetivo del discriminador es no ser engañado.
La competencia entre modelos se denominará "aprendizaje contradictorio", que no debe confundirse con otro tipo de aprendizaje contradictorio que se refiere a la diseño de entradas maliciosas y explotación de límites de decisión débiles en modelos.
El aprendizaje adversario puede estimular modelos, generalmente de diferentes tipos, en los que el desempeño de un modelo puede representarse en relación con el desempeño de otros. Todavía queda mucha investigación por hacer en el campo del aprendizaje antagónico, con la red antagónica generativa como la única creación destacada del subcampo.
El aprendizaje competitivo, por otro lado, es similar al aprendizaje contradictorio, pero se realiza en la escala de nodo por nodo: los nodos compiten por el derecho a responder a un subconjunto de los datos de entrada. El aprendizaje competitivo se implementa en una 'capa competitiva', en la que un conjunto de neuronas son todas iguales, excepto por algunos pesos distribuidos aleatoriamente.
El vector de peso de cada neurona se compara con el vector de entrada y se activa la neurona con la mayor similitud, la neurona 'el ganador se lo lleva todo' (salida = 1). Los demás están 'desactivados' (salida = 0). Esta técnica no supervisada es un componente central de mapas autoorganizados y descubrimiento de características.
Otro ejemplo interesante de aprendizaje compuesto está en búsqueda de arquitectura neuronal. En términos simplificados, una red neuronal (generalmente recurrente) en un entorno de aprendizaje por refuerzo aprende a generar la mejor red neuronal para un conjunto de datos: ¡el algoritmo encuentra la mejor arquitectura para usted! Puedes leer más sobre la teoría. aquí e implementación en Python aquí.
Los métodos de conjunto también son un elemento básico en el aprendizaje compuesto. Los métodos de conjuntos profundos han demostrado ser muy eficaz, y el apilamiento de modelos de extremo a extremo, como codificadores y decodificadores, ha ganado popularidad.
Gran parte del aprendizaje compuesto consiste en descubrir formas únicas de crear conexiones entre diferentes modelos. Se basa en la idea de que,
Un solo modelo, incluso uno muy grande, funciona peor que varios modelos/componentes pequeños, cada uno delegado para especializarse en parte de la tarea.
Por ejemplo, considere la tarea de construir un chatbot para un restaurante.

Podemos segmentarlo en tres partes separadas: bromas/charla, recuperación de información y una acción, y diseñar un modelo para especializarnos en cada una. Alternativamente, podemos delegar un modelo singular para realizar las tres tareas.
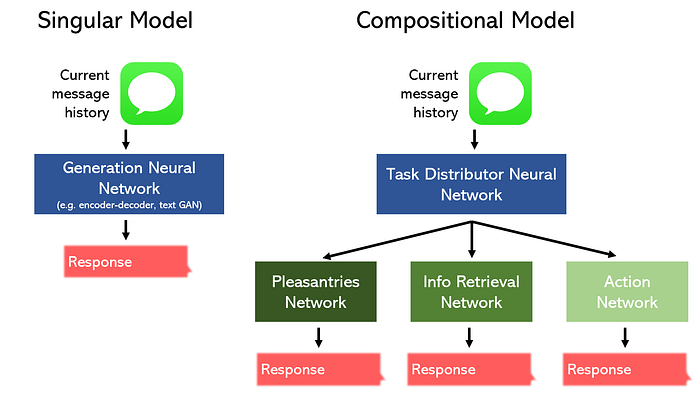
No debería sorprender que el modelo de composición pueda funcionar mejor ocupando menos espacio. Además, este tipo de topologías no lineales se pueden construir fácilmente con herramientas como API funcional de Keras.
Para procesar una diversidad cada vez mayor de tipos de datos, como videos y datos tridimensionales, los investigadores deben construir modelos de composición creativos.
Más información sobre el aprendizaje compositivo y el futuro aquí.
Aprendizaje Reducido
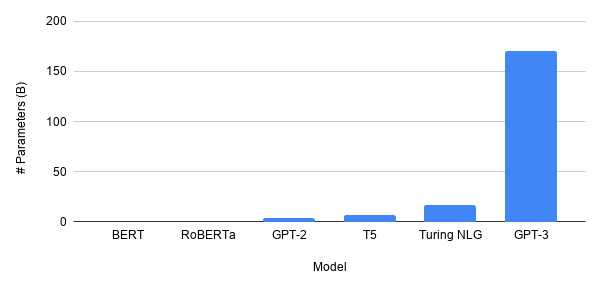
El tamaño de los modelos, particularmente en NLP, el epicentro de la emoción frenética en la investigación de aprendizaje profundo, está creciendo, por mucho. El modelo GPT-3 más reciente tiene 175 mil millones parámetros comparándolo con BERT es como comparar a Júpiter con un mosquito (bueno, no literalmente). ¿Es más grande el futuro del aprendizaje profundo?
Muy discutible, no. Es cierto que GPT-3 es muy poderoso, pero ha demostrado repetidamente en el pasado que las "ciencias exitosas" son las que tienen el mayor impacto en la humanidad. Cada vez que la academia se aleja demasiado de la realidad, por lo general se desvanece en la oscuridad. Este fue el caso cuando las redes neuronales fueron olvidadas a finales de 1900 por un breve período de tiempo porque había tan pocos datos disponibles que la idea, por ingeniosa que fuera, era inútil.
GPT-3 es otro modelo de lenguaje y puede escribir texto convincente. ¿Dónde están sus aplicaciones? Sí, podría generar, por ejemplo, respuestas a una consulta. Sin embargo, hay formas más eficientes de hacer esto (por ejemplo, atravesar un gráfico de conocimiento y usar un modelo más pequeño como BERT para generar una respuesta).
Simplemente no parece ser el caso de que el tamaño masivo de GPT-3, sin mencionar un modelo más grande, sea factible o necesario dado un secando de potencia computacional.
"La ley de Moore se está quedando sin fuerza".
- satya nadella, CEO de Microsoft
En su lugar, nos estamos moviendo hacia un mundo integrado por IA, donde un refrigerador inteligente puede pedir alimentos automáticamente y los drones pueden navegar por ciudades enteras por su cuenta. Los métodos potentes de aprendizaje automático deberían poder descargarse en PC, teléfonos móviles y chips pequeños.
Esto requiere una IA liviana: hacer que las redes neuronales sean más pequeñas y mantener el rendimiento.
Resulta que, directa o indirectamente, casi todo en la investigación de aprendizaje profundo tiene que ver con la reducción de la cantidad necesaria de parámetros, lo que va de la mano con la mejora de la generalización y, por lo tanto, del rendimiento. Por ejemplo, la introducción de capas convolucionales redujo drásticamente la cantidad de parámetros necesarios para que las redes neuronales procesen imágenes. Las capas recurrentes incorporan la idea del tiempo mientras usan los mismos pesos, lo que permite que las redes neuronales procesen secuencias mejor y con menos parámetros.
Las capas incrustadas asignan explícitamente entidades a valores numéricos con significados físicos, de modo que la carga no recae sobre parámetros adicionales. En una interpretación, Abandonar las capas bloquean explícitamente el funcionamiento de los parámetros en ciertas partes de una entrada. Regularización L1/L2 se asegura de que una red utilice todos sus parámetros asegurándose de que ninguno de ellos crezca demasiado y que cada uno maximice su valor de información.
Con la creación de capas especializadas, las redes requieren cada vez menos parámetros para datos más grandes y complejos. Otros métodos más recientes buscan explícitamente comprimir la red.
Poda de redes neuronales busca eliminar sinapsis y neuronas que no aportan valor a la salida de una red. A través de la poda, las redes pueden mantener su rendimiento mientras se eliminan casi por completo.
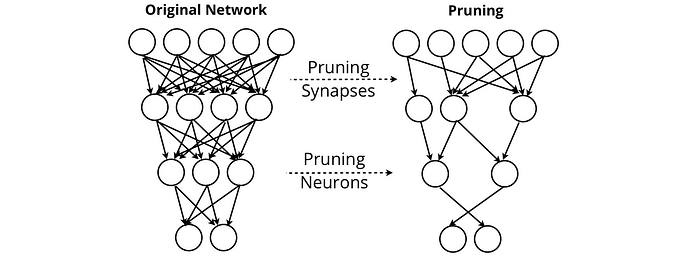
Otros métodos como Destilación del conocimiento del paciente encontrar métodos para comprimir modelos de lenguaje grandes en formularios descargables, por ejemplo, en los teléfonos de los usuarios. Esta fue una consideración necesaria para la Sistema de traducción automática neuronal de Google (GNMT), que impulsa Google Translate, que necesitaba crear un servicio de traducción de alto rendimiento al que se pudiera acceder sin conexión.
En esencia, el aprendizaje reducido se centra en el diseño centrado en la implementación. Esta es la razón por la cual la mayoría de las investigaciones sobre aprendizaje reducido provienen del departamento de investigación de las empresas. Un aspecto del diseño centrado en la implementación es no seguir ciegamente las métricas de rendimiento en los conjuntos de datos, sino centrarse en los posibles problemas cuando se implementa un modelo.
Por ejemplo, antes mencionado entradas adversarias son entradas maliciosas diseñadas para engañar a una red. La pintura en aerosol o las calcomanías en los letreros pueden engañar a los autos sin conductor para que aceleren muy por encima del límite de velocidad. Parte del aprendizaje reducido responsable no es solo hacer que los modelos sean lo suficientemente livianos para su uso, sino también asegurarse de que puedan adaptarse a los casos de esquina no representados en los conjuntos de datos.
El aprendizaje reducido quizás reciba la menor atención de la investigación en aprendizaje profundo, porque "logramos lograr un buen rendimiento con un tamaño de arquitectura factible" no es tan atractivo como "logramos un rendimiento de vanguardia con una arquitectura que consiste en de miles de millones de parámetros”.
Inevitablemente, cuando la búsqueda publicitada de una fracción más alta de un porcentaje desaparezca, como lo muestra la historia de la innovación, el aprendizaje reducido, que en realidad es solo aprendizaje práctico, recibirá más atención de la que merece.
Resumen
El aprendizaje híbrido busca cruzar los límites del aprendizaje supervisado y no supervisado. Los métodos como el aprendizaje semisupervisado y autosupervisado pueden extraer información valiosa de datos no etiquetados, algo increíblemente valioso a medida que la cantidad de datos no supervisados crece exponencialmente.
A medida que las tareas se vuelven más complejas, el aprendizaje compuesto deconstruye una tarea en varios componentes más simples. Cuando estos componentes trabajan juntos, o uno contra el otro, el resultado es un modelo más poderoso.
El aprendizaje reducido no ha recibido mucha atención a medida que el aprendizaje profundo pasa por una fase de exageración, pero pronto surgirán la practicidad y el diseño centrado en la implementación.
¡Gracias por leer!
Declaración: solo para intercambio académico. Los derechos de autor de este artículo pertenecen al autor original. Si hay algún problema, póngase en contacto para eliminarlo.